集團(tuán)官網(wǎng)
- 國家級全民數(shù)字素養(yǎng)與技能培訓(xùn)基地
- 河南省第一批產(chǎn)教融合型企業(yè)建設(shè)培育單位
- 鄭州市數(shù)字技能人才(碼農(nóng))培養(yǎng)評價聯(lián)盟
知名網(wǎng)站Medium近日報道稱,百度研究院高級工程師Awni Hannun在參加國際神經(jīng)網(wǎng)絡(luò)協(xié)會舉辦的會議中時提出了一種可識別普通話的新模型,該模型基于百度深度語音學(xué)習(xí)開發(fā),可實現(xiàn)普通話語音查詢功能,識別準(zhǔn)確率高達(dá)94%。

普通話語音識別有兩個難點。第一則是字符數(shù)據(jù)量大。英文只有26個字母,但中文約有8萬個不同的字符。相比于英文,系統(tǒng)要在每次轉(zhuǎn)錄中直接輸出8萬個字符中的其中一個,如此龐大的數(shù)據(jù)量對于系統(tǒng)運(yùn)算能力要求極高。為解決這一問題,研究團(tuán)隊通過收集人們常用詞,篩選出有用的字符。這一方法提高了系統(tǒng)運(yùn)算效率。
第二,在普通話的表述中,聲調(diào)的不同往往會改變一個詞的意思。且在傳統(tǒng)的語音識別中,設(shè)想所有的語音具有相同間距,以至于在轉(zhuǎn)錄時可以忽略它們。但這套理論卻無法轉(zhuǎn)譯普通話。普通話體系極為復(fù)雜,這就語音系統(tǒng)提出了更高的要求。百度通過特殊的語音識別渠道,省去了大量預(yù)處理環(huán)節(jié)來維持音頻的穩(wěn)定間距,再讓模型學(xué)習(xí)何種數(shù)據(jù)可以最有效的轉(zhuǎn)錄,這一做法大大降低了語音識別的難度。

在談及百度深度語音系統(tǒng)對比Skype翻譯的優(yōu)勢時,Hannum分析認(rèn)為,百度的優(yōu)勢在于學(xué)習(xí)能力。每條音軌中包含三個模塊,即語音轉(zhuǎn)錄模塊、機(jī)器翻譯模塊和語音合成模塊。百度深度語音系統(tǒng)則不同于以往的語音轉(zhuǎn)錄系統(tǒng),它并沒有大量預(yù)處理環(huán)節(jié),而是直接輸入音頻文件,再通過深度神經(jīng)網(wǎng)絡(luò)輸出字符。深度神經(jīng)網(wǎng)絡(luò)則需要大量數(shù)據(jù),去學(xué)習(xí)哪些輸入信息可將語音轉(zhuǎn)譯成正確的普通話。與Skype不同,百度希望將該系統(tǒng)作為所有智能設(shè)備的語音接口,嵌入到可穿戴設(shè)備或語音識別應(yīng)用中,而不僅僅將它定義為一款語音搜索產(chǎn)品。
Medium報道指出,深度學(xué)習(xí)作為該系統(tǒng)的核心,發(fā)揮了極其重要的角色。隨著機(jī)器翻譯和語音識別技術(shù)發(fā)展趨于成熟,人們更多的希望機(jī)器完成輸出任務(wù)。而深度學(xué)習(xí)系統(tǒng)的加入則在增加數(shù)據(jù)量的同時,簡化音頻軌道,通過不斷的學(xué)習(xí)將機(jī)器獲取的信息有效輸出。這也是Hannum看好深度學(xué)習(xí)的原因。
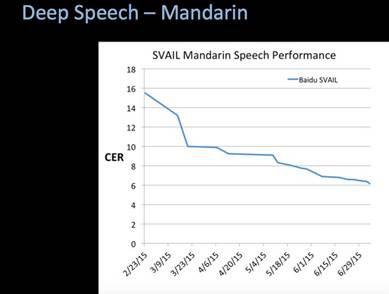
深度語音識別系統(tǒng)出色的成績背后是所有全中文數(shù)據(jù)超過10萬億次運(yùn)算學(xué)習(xí)的成果。且該系統(tǒng)還在尋找更多的關(guān)于各地方言及口音的信息,擴(kuò)大系統(tǒng)訓(xùn)練數(shù)據(jù)。目前,該系統(tǒng)支持超過26萬億次浮點運(yùn)算,可在幾天內(nèi)完成深度語言的集中訓(xùn)練,提高系統(tǒng)學(xué)習(xí)效率。數(shù)據(jù)集與學(xué)習(xí)效率的不斷完善將使百度深度語音識別系統(tǒng)在識別準(zhǔn)確率進(jìn)一步提升。
對于深度學(xué)習(xí)的未來,Hannum認(rèn)為將該模型在更小的系統(tǒng)上運(yùn)行是重要的趨勢之一。大量實驗表明,將現(xiàn)有的學(xué)習(xí)模型壓縮成小模型后,表現(xiàn)依舊穩(wěn)定。這將使深度學(xué)習(xí)系統(tǒng)植入手機(jī)等移動設(shè)備成為現(xiàn)實。
Copyright ? 2013-2021 河南云和數(shù)據(jù)信息技術(shù)有限公司 豫ICP備14003305號  ISP經(jīng)營許可證:豫B-20160281
ISP經(jīng)營許可證:豫B-20160281